
Entendendo na Prática
O que é GraphQL?
Uma linguagem de consulta para APIs onde o cliente define exatamente o que quer receber.
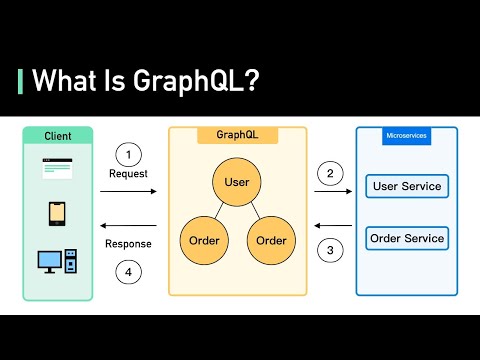
GraphQL e uma linguagem de consulta para APIs e um runtime para executar essas consultas, desenvolvido internamente pelo Facebook em 2012 e publicado como open source em 2015. Diferente do REST, onde o servidor define a estrutura das respostas, no GraphQL o cliente específica exatamente quais campos quer em cada requisição. Isso elimina dois problemas clássicos do REST: o over-fetching, que e receber mais dados do que o necessário, e o under-fetching, que e precisar de múltiplas requisições para obter todos os dados de que precisa. Toda a API GraphQL tem um único endpoint, geralmente /graphql, e o cliente envia queries ou mutations descrevendo precisamente o que precisa.
Como funciona uma Query GraphQL
O cliente descreve o shape dos dados que quer e o servidor retorna exatamente isso.
Em GraphQL, uma query e uma declaração do que o cliente precisa. Por exemplo, para buscar um usuário com apenas nome e email, sem os outros 20 campos que a entidade tem: query { usuário(id: "123") { nome email } }. O servidor retorna exatamente isso: { "data": { "usuário": { "nome": "Ana", "email": "[email protected]" } } }. Para buscar um usuário com seus pedidos e os produtos de cada pedido em uma única requisição: query { usuário(id: "123") { nome pedidos { id total itens { produto { nome preço } } } } }. Em REST, isso exigiria pelo menos 3 requisições diferentes. Em GraphQL, e uma única chamada que retorna exatamente os dados necessários, com a estrutura que o cliente precisa.
Mutations e Subscriptions
Mutations alteram estado. Subscriptions permitem atualizações em tempo real via WebSocket.
GraphQL tem três tipos de operações. Queries são leituras, como já vimos. Mutations são operações que alteram o estado: mutation { criarPedido(input: { produtoId: "456", quantidade: 2 }) { id total status } }. Subscriptions são conexões persistentes via WebSocket que enviam dados ao cliente cada vez que um evento ocorre no servidor. Por exemplo: subscription { pedidoAtualizado(pedidoId: "789") { status estimativaEntrega } }, o cliente recebe atualizações em tempo real cada vez que o pedido muda de status, sem polling. Subscriptions são um dos recursos mais poderosos do GraphQL para aplicações que precisam de dados em tempo real, como chats, dashboards e rastreamento de entrega.
Exemplo prático: app mobile com muitas telas
Cada tela busca apenas os campos que exibe, sem sobrecarga de dados.
Em um app mobile com GraphQL, a tela de lista de produtos pode buscar: { produtos { id nome preço imagemThumb } }, apenas 4 campos. Ao abrir o detalhe do produto, a query expande: { produto(id: "123") { nome descrição preço estoque imagens avaliações { nota texto autor } } }. A tela do perfil do usuário busca: { me { nome avatar pedidosRecentes { id status } } }. Cada tela define exatamente o que precisa. Em um app com dezenas de telas, isso significa dezenas de queries otimizadas em vez de endpoints genéricos que retornam dados demais ou de menos. O resultado e menor consumo de dados mobile, carregamento mais rápido e menos lógica de transformação no cliente.
Exemplo prático: BFF (Backend for Frontend)
GraphQL como camada de orquestração entre o cliente e múltiplos microservicos.
Uma das aplicações mais poderosas do GraphQL e como BFF (Backend for Frontend). O servidor GraphQL expoe um schema unificado para o cliente e internamente chama vários microservicos REST ou gRPC para compor as respostas. O cliente web ou mobile faz uma única chamada GraphQL perguntando por dados de usuário, pedidos e recomendações. O servidor GraphQL faz chamadas paralelas ao serviço de usuários, ao serviço de pedidos e ao serviço de recomendações, combina os resultados e retorna tudo numa única resposta. O cliente ganha simplicidade. Os microservicos ficam desacoplados entre si. E o GraphQL server atua como a camada de orquestração inteligente que conhece como compor os dados de cada serviço.
Quando usar GraphQL
Múltiplos clientes com necessidades diferentes, dados relacionados e performance mobile crítica.
GraphQL brilha quando: a aplicação tem múltiplos clientes (web, mobile, TV) com necessidades diferentes para os mesmos dados; as entidades tem muitas relações e o cliente frequentemente precisa de dados de múltiplas entidades em uma única requisição; a performance de rede e crítica, como em apps mobile onde cada byte economizado importa; e quando diferentes times evoluem o schema de forma independente com versioning de campos. Grandes empresas como Facebook, GitHub, Shopify, Twitter e Airbnb adotaram GraphQL exatamente por esses motivos. O GitHub GraphQL API permitiu que o GitHub reduzisse o número de requisições de seus clientes em 50%.
Quando não usar GraphQL
APIs simples, caching CDN e equipes pequenas sem necessidade de flexibilidade.
GraphQL não e a escolha certa para todos os cenários. Para APIs simples com poucos recursos e clientes com necessidades uniformes, REST e mais simples e suficiente. GraphQL dificulta o caching HTTP nativo porque usa POST para queries e tem um único endpoint, o que torna CDNs e caches de borda menos eficazes. Para quem começa do zero com uma API simples, o overhead de aprender e configurar GraphQL (schema, resolvers, N+1 problem, dataloader) pode não valer a pena. Também não e ideal para APIs públicas de consumo geral onde você não controla todos os clientes, pois a flexibilidade do GraphQL pode ser usada para gerar queries extremamente custosas se não houver depth limiting e query complexity analysis.
O problema N+1 e o DataLoader
Sem otimização, GraphQL pode gerar centenas de queries desnecessárias ao banco.
O problema N+1 e um dos maiores desafios do GraphQL. Se você tem uma query que busca 100 pedidos e para cada pedido busca o cliente, sem otimização o resolver vai fazer 1 query de pedidos + 100 queries de clientes = 101 queries ao banco. O DataLoader, criado pelo Facebook, resolve isso com batching e caching: em vez de executar 100 queries individuais, ele agrupa todas as requisições de clientes e faz 1 única query com todos os IDs: SELECT * FROM clientes WHERE id IN (1, 2, ..., 100). O resultado são 2 queries no total em vez de 101. DataLoader e praticamente obrigatório em qualquer servidor GraphQL de produção com entidades relacionadas para evitar sobrecarga no banco de dados.
Segurança e limites em GraphQL
Depth limiting, query complexity e persisted queries previnem abuso da API.
GraphQL requer atenção especial a segurança. Sem limites, um cliente malicioso pode enviar uma query extremamente profunda e custosa. Depth limiting define o nível máximo de aninhamento permitido. Query complexity analysis atribui um custo a cada campo e rejeita queries acima de um limite. Rate limiting por IP ou por token protege contra abuso. Persisted queries (onde o cliente envia apenas um hash de uma query pre-aprovada) são usadas por grandes plataformas para garantir que apenas queries conhecidas e otimizadas sejam executadas em produção. Introspection deve ser desabilitada em produção para não revelar o schema completo da API a atacantes.
Resumo final
GraphQL resolve problemas reais do REST, mas exige investimento em arquitetura e segurança.
GraphQL e uma ferramenta poderosa para APIs com múltiplos clientes e dados altamente relacionados. Sua flexibilidade de consulta, suporte a tempo real via subscriptions e capacidade de compor dados de múltiplas fontes o tornam ideal para aplicações complexas. O investimento em aprender o modelo de resolvers, lidar com o problema N+1 e implementar segurança adequada e real, mas os beneficios em performance e produtividade de desenvolvimento são significativos nos contextos certos. Para a maioria das APIs simples, REST ainda e a escolha mais prática. Para aplicações com necessidades avançadas de dados, GraphQL pode ser transformador.
Tutoriais em Video

Learn GraphQL In 40 Minutes
What Is GraphQL? REST vs. GraphQL
What Is GraphQL?

GraphQL: The Mental Model

REST vs GraphQL - Whats the best kind of API?

Building Modern APIs with GraphQL
Conceitos-chave
Query
Operação de leitura, o cliente específica exatamente quais campos quer retornar
Mutation
Operação de escrita, cria, atualiza ou deleta dados no servidor
Subscription
Conexão persistente via WebSocket para atualizações em tempo real
Resolver
Função que busca os dados para cada campo do schema
Schema
Definição dos tipos, campos e operações disponíveis na API
DataLoader
Solução para o problema N+1, agrupa múltiplas requisições em uma única query
GraphQL no Instagram
@bytebytego
Reels, GraphQL
@bytebytego
GraphQL no Facebook
GraphQL no X (Twitter)
Links Uteis
O que devs dizem
Migrar para GraphQL no nosso app foi transformador. Cada tela busca exatamente o que precisa. O carregamento ficou 40% mais rápido no mobile porque paramos de buscar dezenas de campos que nunca eram exibidos.
O problema N+1 nos pegou na primeira semana em produção. O banco de dados estava sendo sobrecarregado. Depois de implementar DataLoader, o número de queries caiu 95%. E obrigatório aprender isso antes de colocar GraphQL em produção.
Usamos GraphQL como BFF para orquestrar 7 microservicos. O frontend faz uma única chamada e recebe todos os dados compostos. A experiência de desenvolvimento do time de frontend melhorou muito, eles tem total autonomia para buscar o que precisam.
Comentários
Deixar um comentárioVocê precisa ter uma conta no CuritibaBlog para comentar.