
Entendendo na Prática
O que é um índice em banco de dados?
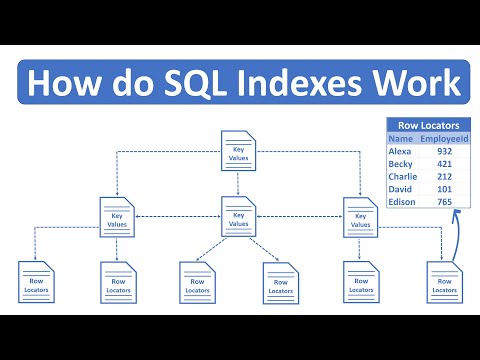
Um índice e uma estrutura auxiliar que acelera buscas trocando espaço por velocidade.
Um índice e uma estrutura de dados adicional criada separadamente da tabela principal. Ele organiza os valores de uma ou mais colunas de forma que o banco consiga localizar linhas rapidamente sem percorrer a tabela inteira. A analogia clássica e o índice de um livro: em vez de ler todas as páginas para encontrar um tópico, você consulta o índice e vai direto a página certa. No banco de dados, o custo de criar um índice e espaço adicional em disco e tempo extra em operações de escrita. O beneficio e leituras exponencialmente mais rápidas. Para tabelas com milhões de linhas, um índice bem planejado e a diferença entre uma query de 50ms e uma de 30 segundos.
Como funciona o B-tree
A árvore balanceada e a estrutura de índice usada pela maioria dos bancos relacionais.
O tipo de índice mais comum em bancos relacionais, PostgreSQL, MySQL, Oracle, e o B-tree, ou árvore B. Uma árvore B e uma estrutura de árvore auto-balanceada onde cada no pode ter múltiplos filhos. Os dados são ordenados nos nos da árvore, permitindo buscas eficientes por igualdade (WHERE id = 42) e por faixa (WHERE idade BETWEEN 20 AND 30). A profundidade da árvore cresce muito lentamente em relação ao número de registros, uma tabela com 1 bilhao de linhas tem uma árvore B com apenas 30 níveis aproximadamente. Isso significa que qualquer linha pode ser encontrada com no máximo 30 leituras de disco, independentemente do tamanho da tabela.
Full table scan vs index scan
Sem índice, o banco le todas as linhas. Com índice, vai direto ao resultado.
Quando uma query não tem índice disponível para a coluna filtrada, o banco executa um full table scan: le cada linha da tabela para verificar se satisfaz a condição. Para tabelas pequenas isso e aceitável. Para tabelas com milhões de linhas, e catastrófico. Um index scan usa o índice para localizar os ponteiros para as linhas relevantes e busca somente elas. A diferença de performance pode ser de 100x a 1000x. O comando EXPLAIN ou EXPLAIN ANALYZE no PostgreSQL mostra exatamente qual estratégia o banco esta usando para cada query e qual e o custo estimado de cada operação.
Índices compostos
Índices em múltiplas colunas, a ordem das colunas importa para a seletividade.
Um índice composto cobre duas ou mais colunas. Por exemplo, um índice em (user_id, created_at) acelera queries que filtram por user_id ou por user_id E created_at. A regra do prefixo mais a esquerda e fundamental: um índice em (a, b, c) serve para queries que filtram por a, por a e b, ou por a, b e c. Mas não serve para queries que filtram apenas por b ou por c. A ordem das colunas no índice composto deve ser definida com base nas queries mais frequentes. A coluna com maior seletividade, que filtra mais linhas, geralmente fica primeiro. Um índice composto bem planejado pode eliminar a necessidade de múltiplos índices separados.
Índices parciais
Indexar apenas as linhas relevantes torna o índice menor e mais eficiente.
Um índice parcial indexa apenas as linhas que satisfazem uma condição específica. No PostgreSQL: CREATE INDEX ON pedidos (user_id) WHERE status = 'pendente'. Isso cria um índice muito menor que cobre somente os pedidos pendentes, que são exatamente os que a aplicação precisa buscar com frequência. Para tabelas com distribuições desiguais, como uma tabela de usuários onde 99% estão ativos e 1% estão deletados, um índice parcial em usuários deletados pode ser muito mais eficiente que um índice completo para queries que buscam somente deletados. Índices parciais reduzem custo de armazenamento e de manutenção.
Covering indexes
Um índice que contem todas as colunas necessárias evita acessar a tabela principal.
Um covering index e um índice que contem todas as colunas que uma query precisa, tanto as colunas de filtro quanto as de projeção. Quando o banco encontra um covering index para uma query, ele pode retornar o resultado diretamente do índice sem precisar acessar as linhas da tabela principal. Isso e chamado de index-only scan e e significativamente mais rápido que um index scan regular. No PostgreSQL, o comando CREATE INDEX pode incluir colunas adicionais com INCLUDE: CREATE INDEX ON pedidos (user_id) INCLUDE (total, status). Essa técnica e especialmente eficiente para queries de relatório que retornam poucas colunas de tabelas grandes.
EXPLAIN e EXPLAIN ANALYZE
Esses comandos revelam o plano de execução e o custo real de cada query.
O comando EXPLAIN mostra o plano de execução que o otimizador do banco vai usar para uma query, quais índices serao usados, quais operações de join, qual custo estimado. EXPLAIN ANALYZE executa a query de verdade e mostra o tempo real de cada etapa. Ler o output do EXPLAIN e uma habilidade fundamental para qualquer desenvolvedor que trabalha com banco de dados. Os números mais importantes são o tipo de scan (Seq Scan indica full table scan; Index Scan ou Bitmap Index Scan indicam uso de índice), o custo estimado e o número de linhas retornadas. Comparar o planejado com o real revela quando as estatísticas do banco estão desatualizadas.
Quando índices prejudicam a performance
Excesso de índices degrada escritas e ocupa espaço desnecessário.
Cada índice precisa ser atualizado quando uma linha e inserida, modificada ou deletada. Em tabelas com alto volume de escrita, excesso de índices pode ser um gargalo serio. Um índice em uma coluna de baixa seletividade, como uma coluna booleana com apenas dois valores possíveis, raramente e útil porque o banco frequentemente prefere um full scan. Índices nunca usados ocupam espaço e aumentam o tempo de escrita sem beneficio algum. Em PostgreSQL, a view pg_stat_user_indexes mostra quantas vezes cada índice foi usado. Índices com idx_scan = 0 por longos períodos são candidatos a remoção.
Índices em bancos NoSQL
MongoDB, Elasticsearch e outros NoSQL também usam índices, com suas próprias particularidades.
Índices não são exclusivos de bancos relacionais. MongoDB suporta índices simples, compostos, parciais, TTL (expiram automaticamente) e geoespaciais. Sem índice em MongoDB, uma query faz um collection scan equivalente ao full table scan. O comando explain() em MongoDB mostra o plano de execução assim como o EXPLAIN do PostgreSQL. Elasticsearch usa um índice invertido, estrutura otimizada para busca de texto livre, onde cada termo do texto aponta para os documentos que o contem. Redis não tem índices tradicionais mas oferece estruturas como sorted sets que funcionam como índices ordenados para casos específicos de uso.
Resumo final
O índice certo na coluna certa e um dos investimentos de melhor retorno em performance.
Índices transformam queries lentas em consultas instantâneas. O B-tree e a base de quase todos os índices em bancos relacionais. Full scan versus index scan e a diferença entre segundos e milissegundos. Índices compostos precisam seguir o prefixo mais a esquerda. Índices parciais cobrem casos específicos com menor overhead. Covering indexes eliminam acesso a tabela principal. EXPLAIN revela o que o banco realmente faz com cada query. E o excesso de índices prejudica escritas tanto quanto a falta deles prejudica leituras. O segredo e criar índices baseados nos padrões de acesso reais da aplicação, monitorar seu uso e remover os que não são utilizados.
Tutoriais em Video
How do SQL Indexes Work

Things every developer needs to know about database indexing

Indexing in PostgreSQL vs MySQL

B+Tree Indexes (CMU Intro to Database Systems)

B+Tree Indexes (CMU Fall 2023)

Tree Indexes: B+Trees (CMU)
Conceitos-chave
Índice
Estrutura de dados auxiliar que acelera buscas, troca espaço em disco por velocidade de leitura
B-Tree
Árvore balanceada usada pela maioria dos bancos relacionais, suporta busca por faixa de valores
Index scan vs Full table scan
Com índice o banco leva microsegundos; sem índice percorre linha por linha
Índice composto
Índice em múltiplas colunas, ordem das colunas importa para seletividade
Índice parcial
Índice apenas nas linhas que satisfazem uma condição, menor e mais eficiente
Over-indexing
Excesso de índices acelera leitura mas degrada INSERT/UPDATE/DELETE e ocupa mais espaço
Indexação no Instagram
@bytebytego
Reels
@bytebytego
Indexação no X (Twitter)
Links Uteis
O que devs dizem
Tinha uma query que levava 45 segundos numa tabela de 10 milhões de linhas. Adicionei um índice composto nas colunas de filtro e caiu para 12ms. EXPLAIN foi o que me mostrou exatamente o que estava errado.
O conceito de covering index foi revelador. Para relatorios de dashboard, criar um índice que ja inclui todas as colunas necessárias elimina o acesso a tabela completamente. Performance incrível.
Aprendi da forma mais difícil que excesso de índices em tabela com muito INSERT e UPDATE pode ser tao prejudicial quanto a falta deles. Monitorar idx_scan no PostgreSQL virou rotina para mim.
Comentários
Deixar um comentárioVocê precisa ter uma conta no CuritibaBlog para comentar.