
Entendendo na Prática
O que é monitoramento de aplicações?
E o processo de coletar, visualizar e alertar sobre o comportamento do sistema em produção.
Monitoramento de aplicações e o conjunto de práticas e ferramentas que permitem a uma equipe entender como o sistema se comporta em produção em tempo real. Abrange coleta de métricas (taxa de requisições, latência, uso de CPU e memória), visualização em dashboards e configuração de alertas que notificam o time quando algo sai dos parâmetros normais. O objetivo central e saber que algo esta errado antes que o usuário reclame. Em sistemas modernos distribuídos, o monitoramento e a diferença entre reagir a crises e antecipa-las. Uma aplicação sem monitoramento e uma caixa preta: você só descobre os problemas quando o telefone toca ou o cliente abre um chamado.
Diferença entre monitoramento e observabilidade
Monitoramento responde o que esta errado. Observabilidade responde por que.
Monitoramento e observabilidade são complementares, não substitutos. Monitoramento funciona com métricas e alertas predefinidos: se a taxa de erro passa de 1%, alerta. Se o uso de memória passa de 85%, alerta. E essencial para detecção de problemas conhecidos e para manter SLOs. Observabilidade, com seus três pilares (logs, métricas, traces), permite investigar problemas novos para os quais você não tinha alerta predefinido. Na prática, você precisa dos dois: monitoramento para ser notificado que algo esta errado, e observabilidade para investigar por que. O erro comum e ter monitoramento sem capacidade de investigação, o que resulta em equipes que sabem que há um problema mas não conseguem determinar a causa raiz rapidamente.
Prometheus e métricas
Prometheus coleta métricas por scraping e armazena séries temporais.
Prometheus e um banco de dados de séries temporais open source que se tornou o padrão para monitoramento em ambientes cloud-native. Diferentemente de sistemas push, Prometheus funciona por scraping: ele consulta periodicamente um endpoint /metrics em cada serviço e armazena os dados coletados. As métricas são consultadas com PromQL, uma linguagem expressiva para calcular taxas, percentis e agregações sobre séries temporais. Tipos de métricas no Prometheus: Counter (valor que só cresce como requisições totais), Gauge (valor que sobe e desce como uso de CPU), Histogram (distribuição de valores como latência por bucket) e Summary (percentis pre-calculados). A instrumentação e simples e bibliotecas client existem para todas as linguagens principais.
Grafana e dashboards
Grafana transforma dados brutos de métricas em dashboards visuais acionáveis.
Grafana e uma plataforma de visualização open source que conecta múltiplas fontes de dados como Prometheus, Loki, Elasticsearch e InfluxDB e cria dashboards interativos. Um dashboard de serviço típico mostra taxa de requisições por segundo, latência no percentil 50, 95 e 99, taxa de erros, uso de CPU e memória dos pods e conexões ativas com o banco. O Grafana tem um marketplace de dashboards prontos para as principais tecnologias. Para alertas, o Grafana 8 e versões posteriores tem alertas nativos que funcionam com múltiplas fontes de dados. A combinação Prometheus e Grafana e o stack de monitoramento mais adotado em produção no mundo open source, com documentação extensa e comunidade ativa.
Alertas e on-call
Alertas mal configurados são piores que ausência de alertas por gerarem fadiga.
Alertas são o coração do monitoramento, mas alertas mal configurados destroem a eficiência do time. Alert fatigue ocorre quando o volume de alertas e tao alto que o time começa a ignora-los. A regra de ouro e: um alerta só deve disparar quando requer ação imediata de um ser humano. Alertas que não requerem ação devem ser removidos ou transformados em registros de log. Cada alerta deve ter um runbook associado, um documento que explica o que fazer quando ele dispara. Alertmanager, componente do Prometheus, gerência notificações, agrupa alertas relacionados, silencia alertas durante manutenção e roteia notificações para canais diferentes como Slack, email ou PagerDuty para on-call.
USE Method e RED Method
Dois frameworks que guiam o que monitorar em recursos e em serviços.
Brendan Gregg criou o USE Method para monitoramento de recursos de sistema: Utilization (qual percentual do recurso esta sendo usado), Saturation (quanto trabalho esta esperando pelo recurso) e Errors (falhas do recurso). E ideal para CPU, memória, disco e rede. Para serviços orientados a requisições, o RED Method e mais adequado: Rate (quantas requisições por segundo), Errors (qual a taxa de requisições com erro) e Duration (qual a distribuição de latência). Combinar USE e RED oferece cobertura completa: USE garante que os recursos subjacentes estão saudáveis, RED garante que o serviço esta processando requisições com qualidade adequada do ponto de vista do usuário. Esses dois frameworks eliminam a duvida sobre o que monitorar.
APM, Application Performance Monitoring
APM oferece visibilidade automática sobre o comportamento interno da aplicação.
Application Performance Monitoring vai além das métricas de infraestrutura e oferece visibilidade sobre o comportamento interno da aplicação: quais métodos são mais lentos, quais queries de banco de dados consomem mais tempo, onde o CPU e mais usado no código. Ferramentas como Datadog APM, New Relic, Dynatrace e Elastic APM instrumentam a aplicação automaticamente via agentes e coletam dados de performance granulares. APM e especialmente útil para identificar gargalos que não aparecem nas métricas de infraestrutura, como uma query SQL sem índice que afeta latência mas não esgota a CPU. O custo dessas ferramentas gerenciadas e alto em escala, mas o retorno em tempo de investigação de problemas de performance geralmente justifica para times com SLOs rigorosos.
Synthetic monitoring
Simular ações de usuário periodicamente detecta problemas antes dos usuários reais.
Synthetic monitoring executa ações predefinidas no sistema em intervalos regulares como se fosse um usuário real, para verificar que tudo funciona corretamente. Pode ser tao simples quanto um ping HTTP para verificar que a página retorna 200, ou tao complexo quanto um script Playwright que simula o fluxo completo de checkout, desde a busca de produto até a confirmação de pagamento. Ferramentas como Datadog Synthetics, New Relic Synthetics e Grafana Cloud Synthetic Monitoring oferecem essa capacidade. O valor do synthetic monitoring e detectar degradações antes que usuários reais as percebam, especialmente para fluxos críticos de negócio. Se o checkout esta quebrando e nenhum usuário tentou comprar nos últimos cinco minutos, o synthetic monitoring detecta em segundos.
Black-box vs White-box monitoring
Dois complementares: um testa o que o usuário ve, o outro o que o sistema faz internamente.
Black-box monitoring testa o sistema de fora, como um usuário: envia uma requisição HTTP e verifica que a resposta correta e retornada em tempo adequado. Não sabe nada sobre o interior do sistema, só ve o resultado. E o que synthetic monitoring faz. White-box monitoring tem acesso ao interior: métricas de CPU, conexões de banco, filas internas, traces de código. A combinação e poderosa: black-box alerta que o usuário esta sendo impactado, white-box investiga por que. Times maduros usam ambos: black-box para SLOs orientados ao usuário e white-box para diagnostico de causa raiz. Nenhum substitui o outro, pois cobrem dimensões diferentes da saude do sistema.
Resumo final
Monitoramento eficaz e o que transforma equipes reativas em equipes proativas.
Monitoramento de aplicações e uma das práticas mais fundamentais de engenharia de software em produção. Começar e simples: Prometheus e Grafana são gratuitos e bem documentados, e um dashboard básico com métricas RED pode ser configurado em poucas horas. O que diferencia um monitoramento eficaz de um caos de alertas e a disciplina de alertar apenas sobre o que requer ação, manter runbooks atualizados e revisar alertas periodicamente para remover os que nunca disparam ou que sempre disparam sem consequência. Com USE Method para recursos e RED Method para serviços, você tem cobertura sólida sem sobrecarregar o time. Um sistema bem monitorado não elimina incidentes, mas garante que sejam detectados e resolvidos antes de se tornarem crises.
Tutoriais em Video
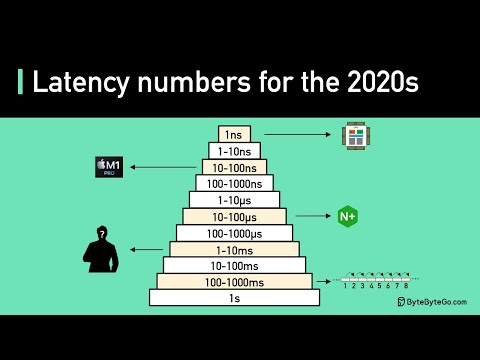
Latency Numbers Programmer Should Know, ByteByteGo

System Design: Apache Kafka In 3 Minutes, ByteByteGo

System Design 101, roadmap.sh
Top 6 Tools to Turn Code into Beautiful Diagrams, ByteByteGo
System Design for Beginners Course, freeCodeCamp

Intro to Architecture and Systems Design Interviews, Jackson Gabbard
Conceitos-chave
Prometheus
Banco de dados de series temporais para métricas, coleta por scraping de endpoints /metrics, PromQL para consultas
Grafana
Plataforma de visualização, dashboards de métricas, logs e traces, integra com Prometheus, Loki, Jaeger
Alertmanager
Componente do Prometheus, gerência alertas, agrupa, silência e envia notificações via Slack, PagerDuty, email
USE Method
Utilization, Saturation, Errors, metodo de Brendan Gregg para monitorar recursos do sistema
RED Method
Rate, Errors, Duration, metodo focado em serviços, quantas requisições, quantas erros, quanto tempo
Synthetic monitoring
Simular ações de usuários reais periodicamente, detectar problemas antes que usuários reclamem
No Instagram
@bytebytego
Reels
@bytebytego
No Facebook
No X (Twitter)
O que devs dizem
Implementamos Prometheus e Grafana em um fim de semana e na semana seguinte ja detectamos um vazamento de memória que causava reinicializações diárias dos pods. O gráfico de memória subindo linearmente era obvio no dashboard. Sem monitoramento nunca teriamos achado antes de afetar usuários.
O RED Method simplificou nossa conversa sobre qualidade de serviço. Em vez de debates subjetivos, agora mostramos o gráfico de P99 de latência e a taxa de erros. Dados objetivos transformam reuniões de postmortem em discussões produtivas sobre causa raiz.
Tinhamos 200 alertas e o time ignorava a maioria. Fizemos uma revisão, removemos 170 que nunca exigiam ação, e agora temos 30 alertas que o time leva a serio. O primeiro mes após a redução, capturamos dois incidentes críticos que antes passariam despercebidos no ruido.
Comentários
Deixar um comentárioVocê precisa ter uma conta no CuritibaBlog para comentar.